一段你每天都在使用,却从未真正理解的浏览器底层身份机制——UserAgent
在日常 Web 开发过程中,我们经常需要识别用户所使用的浏览器类型,以便进行兼容性处理或功能适配。某天,在开发一个简单的前端功能时,我需要判断用户当前使用的浏览器类型。于是我打开控制台,输入了一行最熟悉不过的代码:
navigator.userAgent
浏览器返回了一段极其冗长的信息:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36
第一眼看过去,你可能会和大多数开发者一样产生疑问:这真的是一个“浏览器标识”吗?为什么会包含如此多重复、甚至相互矛盾的信息?为什么 Chrome 里会出现 Safari?为什么几乎所有浏览器都有 Mozilla?
事实上,这一串看似混乱的字符串,背后隐藏着一段长达 30 年的浏览器技术演进史,也是一场关于标准、兼容与市场竞争的长期博弈。
浏览器发展大事年表
理解 UserAgent 的混乱,必须从浏览器的发展历史说起:
- 1990年:Nexus(WorldWideWeb)诞生,世界上第一个浏览器
- 1993年:Mosaic 浏览器问世,首次支持图文混排
- 1994年:Netscape(Mozilla)诞生,开启浏览器商业竞争
- 1995年:Opera 与 Internet Explorer 发布,浏览器大战爆发
- 2002年:Firefox 发布,开源浏览器崛起
- 2003年:Safari 发布,WebKit 引擎登场
- 2008年:Chrome 发布,现代浏览器格局形成

一、UserAgent 的起源:浏览器如何“自报家门”
最早的浏览器由 Tim Berners-Lee 发明,最初命名为 WorldWideWeb,后来更名为 Nexus。虽然它具有划时代意义,但存在一个致命缺陷:不支持图片显示。
随着 Mosaic 浏览器的出现,这一局面被彻底改变。Mosaic 首次实现图文混排,使 Web 页面具备了更强的表现力。
但新的问题也随之产生:服务器如何判断当前访问用户的浏览器是否支持图片、表格或其他高级特性?
答案就是:UserAgent(用户代理)。
浏览器在向服务器发起 HTTP 请求时,会附带一段标识信息,例如:
NCSA_Mosaic/2.0 (Windows 3.1)
服务器可以根据这段信息返回不同内容,实现“内容适配”。这也是 UserAgent 最初的设计目的:标识客户端身份,实现差异化响应。
二、浏览器大战:UserAgent 开始“说谎”
随着 Netscape 浏览器的迅速崛起,UserAgent 开始出现“伪装”现象。
Netscape 在 UA 中使用 Mozilla 标识,即使后来更名为 Navigator,也依然沿用该字段:
Mozilla/1.0 (Win3.1)
随后,Internet Explorer 为了兼容那些只识别 Mozilla 的网站,直接“冒充”Mozilla:
Mozilla/1.22 (compatible; MSIE 2.0; Windows 95)
从这一刻开始,UserAgent 不再是一个“真实身份标识”,而逐渐演变为一种兼容性策略工具。
三、技术继承与历史包袱:Firefox 与 Gecko
Firefox 基于 Gecko 引擎开发,其 UserAgent 中依然保留了多个历史标识:
Mozilla/5.0 (...) Gecko/... Firefox/1.0
这意味着:即使浏览器内核已经发生重大变化,为了兼容旧网站,历史标识依然被保留。这种“向后兼容”的设计,虽然提高了网页可用性,但也让 UA 结构变得越来越复杂。

四、KHTML、WebKit 与 “like Gecko” 的由来
Konqueror 浏览器使用 KHTML 引擎,但为了兼容大量基于 Gecko 优化的网站,它在 UA 中加入了一段经典标识:
(KHTML, like Gecko)
这段“like Gecko”并不代表它真的使用 Gecko 引擎,而是一种兼容声明。这种写法被 WebKit、Blink 等后续引擎继承,并沿用至今,成为现代 UA 的标准结构之一。
五、现代浏览器:统一“伪装体系”
进入 Chrome 时代后,UserAgent 结构进一步复杂化:
- Chrome 使用 Blink 引擎,但仍保留 WebKit 标识
- Safari 使用 WebKit 引擎
- 几乎所有浏览器都包含 Mozilla 字段
最终形成一种奇特现象:所有浏览器都在“假装”彼此。
这种现象本质上是历史兼容性的产物,也是浏览器生态长期博弈的结果。

六、国产浏览器与 UA 混乱升级
在国内环境中,UserAgent 的复杂程度进一步升级:
- 双核浏览器(Trident + WebKit / Blink)
- 基于 Chrome 或 IE 二次开发
- 通过 UA 后缀标识品牌(如 QQBrowser、LBBROWSER)
这类浏览器往往同时兼容多个内核,并在 UA 中叠加多层信息,使解析难度大幅提升。
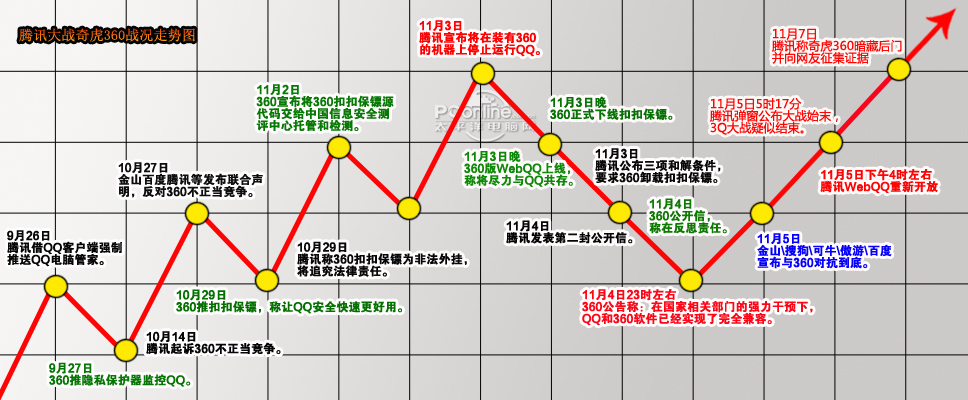
七、典型案例:3Q大战中的 UA 对抗
2010 年 360 与腾讯的冲突中,腾讯曾限制 360 浏览器访问部分服务。
360 的解决方案非常直接:删除 UserAgent 中的 360 标识,实现“隐身访问”。
这一事件再次证明:UserAgent 本质上是可以被修改的,它并不具备安全可信性。
八、标准化尝试:W3C 的努力
面对 UA 混乱的问题,W3C 曾尝试通过规范进行统一:
User Agent Accessibility Guidelines
然而,由于历史兼容负担过重,加上各大浏览器厂商的实现差异,该规范并未彻底解决 UA 混乱问题。
近年来,浏览器厂商开始推动 User-Agent Client Hints,试图替代传统 UA 字符串,提升隐私与可控性。
九、开发者须知:UA 的实际应用与局限
在实际开发中,UserAgent 仍然有其使用价值,但需要谨慎:
- 适用于基础设备识别(移动端 / PC / 平板)
- 不适合用于核心业务逻辑判断(易被伪造)
- 推荐使用 Feature Detection(特性检测)替代 UA 判断
- SEO 场景中可用于识别爬虫,但需结合 IP 与行为分析
查看你的浏览器 UserAgent
如果你想快速查看当前浏览器 UA,可以使用在线工具进行解析:


该工具支持快速识别浏览器、操作系统、设备类型等信息,无需下载安装,适用于开发调试、SEO分析以及安全检测等场景。
总结
UserAgent 从最初的“客户端身份标识”,逐渐演变为一个“历史兼容性产物”。
它既承载了浏览器发展的历史,也体现了 Web 标准演进的复杂性。在现代开发中,我们既要理解它的结构与来源,也要清楚它的局限,合理使用,避免误用。
理解 UserAgent,不仅有助于前端开发与兼容性处理,也能帮助我们更深入地认识整个 Web 技术体系的演进逻辑。
浏览器历史悠久哦